* KNN
》 컴퓨터에게 학습하는 능력을 주는 것이란
⇒ 파라미터를 찾는 것(데이터를 통해 스스로 학습하여 최적의 판단이나 예측 즉, 적절한 파라미터를 찾는 것)
》 KNN(K-Nearest Neighbor) : 탐색할 이웃 수(k), 거리 측정 방법에 따라 분류가 달라짐
》 장점 : 이해하기 매우 쉬운 모델이며, 많이 조정하지 않아도 좋은 성능을 발휘한다. 매우 빠르게 만들 수 있어서 더 복잡한 알고리즘을 적용해 보기 전에 시도해 볼 수 있다.
》 단점 : 훈련 세트가 매우 크면 예측이 느려진다. 많은 특성을 가진 데이터 세트에는 잘 동작하지 않는다. 따라서 예측이 느리고 많은 특성을 처리하는 능력이 부족하여 현업에서는 사용하지 않는다.
- K = Hyperparameter = 임의로 변경할 수 있는 설계 파라미터
- (K 개수 선택)
가. k가 너무 작을 때 : Overfitting
일반화 성능이 낮아진다. 극단적으로 k=1이라고 하자. 그러면 분류 정확도가 상당히 낮을 수밖에 없다. 시야가 좁아지는 거고, 아주 근처에 있는 점 하나에 민감하게 영향을 받기 때문이다.
이를 overfitting(과적합)이라고 한다.
나. k가 너무 클 때 : Underfitting
underfitting은 분류기가 학습 세트의 세세한 부분에 충분히 주의를 기울이지 않았기 때문에 나타난다. 예를 들어 학습 세트에 100개의 점이 있고 k=100으로 설정했다고 극단적으로 가정해보자. 그러면 모든 점이 결국 동일한 방식으로 분류될 거다.(점 사이의 거리는 의미가 없어진다.)
* Unsupervised Leaning(비지도 학습)
- 클러스터링, 군집화를 사용하는 예로는 아래와 같은 것들을 들 수 있다.
가. 추천 엔진 : 사용자 경험을 개인화하기 위해 비슷한 제품 묶어주기
나. 검색 엔진: 관련 주제나 검색 결과 묶어주기
다. 시장 세분화(segmentation): 지역, 인구 통계, 행동에 따라 비슷한 고객들 묶어주기
- 군집화의 목표는 서로 유사한 데이터들은 같은 그룹으로, 서로 유사하지 않은 데이터는 다른 그룹으로 분리하는 것
- 몇개의 그룹으로 묶을 것인가 : K-Means 알고리즘
- 데이터의 “유사도”를 어떻게 정의할 것인가 (유사한 데이터란 무엇인가) : EM 알고리즘
(E는 Expectation, M은 Maximization을 의미)
* Naive Bayes(나이브 베이즈)
》 스팸 메일 필터, 텍스트 분류, 감정 분석, 추천 시스템 등에 광범위하게 활용되는 분류 기법
》 베이즈 정리에 기반한 통계적 분류 기법이며, 가장 단순한 지도 학습 (supervised learning) 중 하나
》 분류기는 빠르고, 정확하며, 믿을만한 알고리즘 정확성도 높고 대용량 데이터에 대해 속도도 빠르다.
》 feature끼리 서로 독립이라는 조건이 필요.
즉, 스팸메일 분류에서 광고성 단어의 개수와 비속어의 개수가 서로 연관이 있어서는 안됨.
》 장점
- 간단하고, 빠르며, 정확한 모델.
- computation cost가 작다. (따라서 빠름.)
- 큰 데이터셋에 적합하다.
- 연속형보다 이산형 데이터에서 성능이 좋다.
- Multiple class 예측을 위해서도 사용할 수 있다.
》 단점 : 장점이 많지만 feature가 서로 독립이어야 한다는 크리티컬한 단점이 있다. (하지만 실제 데이터에서 모든 feature가 독립인 경우는 드물다)
》 zero frequency: 만약 training data set 중 스팸 메일에서 '당첨'이라는 단어가 없었다면, 분류기는 항상 p(X=1|spam)=0으로 취급하여 '당첨'이라는 단어가 들어가면 무조건 스팸이 아니라고 분류해버린다. 이것을 'Zero Frequency'라고 부름
* 베이지 이론(Bayes Theorem) : 이전의 경험과 현재의 증거를 토대로 어떤 사건의 확률을 추론하는 알고리즘
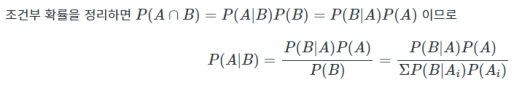
》 P(A|B) : PDA(우리가 알고 싶은 것)
》 P(B|A) : Likelihood(현재의 증거)
》 P(B) : Prior(이전의 경험)
* Optimal Classification(Bayes)
- 우리가 아는 모델 : f(X) 와 결과값 : Y의 오차를 최소화 할 수 있는 모델을 찾는 것 = 머신러닝
* Naive Bayes Classifier

- 베이지안 추론 : 추론 대상에 대한 사전분포를 알고, 데이터에 대한 적절한 가정(likelihood, f(x|θ))만 할 수 있다면, 우리는 이로부터 사후분포에 대해 추론할 수 있다
* Q1 : P(Yes | Overcast, Mild) <= NaiveBayes 문제
→ 날씨가 흐리고, 온도가 온화할 때 게임할 수 있는 확률
| whether | Temperature | play |
| Sunny | Hot | No |
| Sunny | Hot | No |
| Overcast | Hot | Yes |
| Rainy | Mild | Yes |
| Rainy | Cool | Yes |
| Rainy | Cool | No |
| Overcast | Cool | Yes |
| Sunny | Mild | No |
| Sunny | Cool | Yes |
| Rainy | Mild | Yes |
| Sunny | Mild | Yes |
| Overcast | Mild | Yes |
| Overcast | Hot | Yes |
| Rainy | Mild | No |

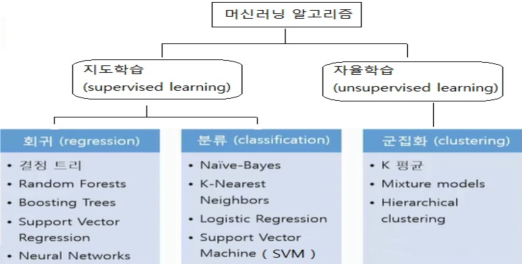
* Decision Tree(지도학습 모델)
- 랜덤 포레스트의 기본 단위 인 의사결정트리 말그대로 의사를 결정하는데 이진형 답변의 연속 모델로 스무고개와 비슷하게 예/아니오의 대답으로 최종 답변이 결정되는 구조
* 엔트로피란 : 불확실성을 나타내는데, 정보량의 평균
》 (=)불순도를 측정하는 지표로서, 정보량의 기댓값
》 정보량이란 어떤 사건이 가지고 있는 정보의 양을 의미하며, 이는 식으로 다음과 같다.

》 ID3알고리즘 : Entropy를 작게 하는 방향으로 가지를 뻗어나가면서 의사결정나무를 키워나가는 알고리즘
(단, 독립변수가 모두 범주형일 때만 가능연속형 변수는 C4.5 알고리즘)
* 지니계수(Gini Index) : 불순도를 측정하는 지표로서, 데이터의 통계적 분산 정도를 정량화해서 표현한 값
》 CART 알고리즘
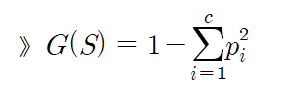
》 장점
- 쉽고 직관적이다
- 이상치와 노이즈에 큰영향을 받지않음
- 비모수적 모형: 선형성/정규성/등분산성 등 가정이 필요없는 방법
- 모델의 해석력이 높음
- 연속형/이산형 데이터 모두 다룰 수 있음
》 단점
- 과적함(overfitting)의 가능성이 높음
- 모델의 유연성이 떨어짐(일반성 부족)
- 학습데이터에 따라 생성되는 의사결정나무에 큰 차이가 있음
》 overfitting 해결방법 : 가지치기, 앙상블(Random Forest)
* 앙상블(Ensemble) : 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
》 여러개의 모델을 학습시켜 그 모델들의 예측결과들을 이용해 하나의 모델보다 더 나은 값을 예측하는 방법
》 큰 데이터 세트가 있을 때, 데이터 세트를 나누어 독립적으로 운영되는 각각의 머신러닝을 통해 학습시킨 뒤 모델을 합쳐 전체 데이터의 결과를 산출하는 방법이다
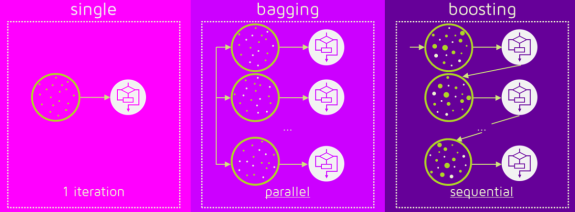
* 앙상블 학습의 유형 : 보팅(Voting), 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)
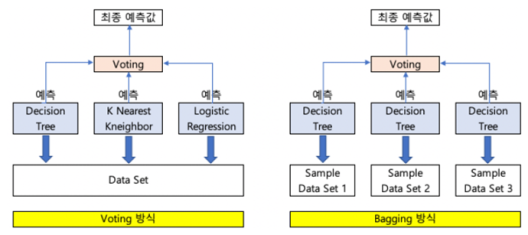
》 Hard voting: 분류기의 예측값(레이블)을 가지고 다수결 투표를 통해 최종 앙상블 예측
》 Soft voting: 분류기의 예측값(레이블)의 확률을 가지고 평균을 구한 뒤, 평균이 가장 높은 클래스로 최종 앙상블 예측
》 배깅(Bagging)은 Bootstrap Aggregating의 약자로, 보팅(Voting)과는 달리 동일한 알고리즘으로 여러 분류기를 만들어 보팅으로 최종 결정하는 알고리즘
샘플을 여러 번 뽑아 각 모델(같은 모델)을 학습시켜 결과를 집계(Aggregating) 하는 방법
》 배깅진행방식
(1) 동일한 알고리즘을 사용하는 일정 수의 분류기 생성
(2) 각각의 분류기는 부트스트래핑(Bootstrapping) 방식으로 생성된 샘플데이터를 학습
(3) 최종적으로 모든 분류기가 보팅을 통헤 예측 결정
※ 부트스트래핑 샘플링은 전체 데이터에서 일부 데이터의 중첩을 허용하는 방식
》 부스팅(boosting) : 성능이 약한 학습기(weak learner)를 여러 개 연결하여 강한 학습기(strong learner)를 만드는 앙상블 학습 방법
부스팅 방법의 아이디어는 앞에서 학습된 모델을 보완해 나가면서 더 나은 모델로 학습시키는 것
그 중 가장 유명하고 인기 있는 모델 아다부스트 (AdaBoost, Adaptive Boosting)
》 Boosting VS Bagging : 동일하게 복원 랜덤 샘플링을 하지만, 가중치를 부여한다는 차이점
Bagging이 병렬로 학습하는 반면, Boosting은 순차적으로 학습하고, 학습이 끝나면 나온 결과에 따라 가중치가 재분배
》 보팅 : 여러 종류의 알고리즘을 사용한 각각의 결과에 대해 투표를 통해 최종 결과를 예측하는 방식
》 배깅 : 같은 알고리즘에 대해 데이터 샘플을 다르게 두고 학습을 수행해 보팅을 수행하는 방식(데이터 샘플은 중첩이 허용)
》 부스팅 : 여러 개의 알고리즘이 순차적으로 학습을 하되, 앞에 학습한 알고리즘 예측이 틀린 데이터에 대해 올바르게 예측할 수 있도록, 그 다음번 알고리즘에 가중치를 부여하여 학습과 예측을 진행하는 방식
》 스태킹 : 여러 가지 다른 모델의 예측 결과값을 다시 학습 데이터로 만들어 다른 모델(메타 모델)로 재학습시켜 결과를 예측하는 방법
* Random Forest : 여러 개의 결정트리(Decision Tree)를 활용한 배깅 방식의 대표적인 알고리즘
》 장점 :
- 결정 트리의 쉽고 직관적인 장점을 그대로 가지고 있음
- 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가짐
- 다양한 분야에서 좋은 성능을 나타냄
》 단점 :
- 하이퍼 파라미터가 많아 튜닝을 위힌 시간이 많이 소요됨
* SVM(Support Vector Machine)
》 데이터를 선형으로 분리하는 최적의 선형 결정 경계를 찾는 알고리즘(수학적으로 풀어서 최적의 경계선을 찾는 기법)
- 마진을 최대화하는 분류 경계면을 찾는 기법
》 딥러닝 이전 뛰어난 성능의 대표 기계학습 알고리즘(2인자)
》 서포트 벡터 머신(SVM)은 결정 경계(Decision Boundary), 즉 분류를 위한 기준 선을 정의하는 모델
- 분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행할 수 있게 된다.
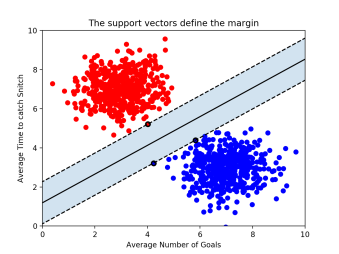
- 최적의 결정 경계(Decision Boundary) : 데이터 군으로부터 최대한 멀리 떨어지는 게 좋다.
- Margin Distance : 마진(Margin)은 결정 경계와 서포트 벡터 사이의 거리를 의미함. 가운데 실선이 하나 그어져 있는데, 이것이 바로 ‘결정 경계’, 점선으로부터 결정 경계까지의 거리가 바로 ‘마진(margin)’ 최적의 결정 경계는 마진을 최대화한다.
- x축과 y축 2개의 속성을 가진 데이터로 결정 경계를 그었는데, 총 3개의 데이터 포인트(서포트 벡터)가 필요 즉, n개의 속성을 가진 데이터에는 최소 n+1개의 서포트 벡터가 존재한다는 걸 알 수 있다.
* 이상치(Outlier)
》 하드 마진(hard margin) : 아웃라이어를 허용하지 않고 기준을 까다롭게 세운 모양, 서포트벡터와 결정 경계 사이의 거리가 매우 좁다. 즉, 마진이 매우 작아진다. 이렇게 개별적인 학습 데이터들을 다 놓치지 않으려고 아웃라이어를 허용하지 않는 기준으로 결정 경계를 정해버리면 오버피팅(overfitting) 문제가 발생할 수 있다.
》 소프트 마진(soft margin) : 아웃라이어들이 마진 안에 어느정도 포함되도록 너그럽게 기준을 잡았다. 이렇게 너그럽게 잡아 놓으니 서포트벡터와 결정 경계 사이의 거리가 멀어졌다. 즉, 마진이 커진다. 대신 너무 대충대충 학습하는 꼴이라 언더피팅(underfitting) 문제가 발생할 수 있다.
* kernelizedsupport vector machines :
입력 데이터에서 단순한 초평면 hyperplane으로 정의되지 않는 더 복잡한 모델을 만들 수 있도록 확장한 것, 직선과 초평면은 유연하지 못하여 저차원 데이터셋 에서는 선형 모델이 매우 제한적 선형 모델을 유연하게 만드는 한 가지 방법은 특성끼리 곱하거나 특성을 거듭제곱하는 식으로 새로운 특성을 추가하는 것
》 커널(Kernel) : 아무리 봐도 단순한 선형으로는 도저히 해결이 안되는 문제들이 존재, 이때 다항식(polynomial) 커널을 사용하면 2차원에서 x, y 좌표로 이루어진 점들을 아래와 같은 식에 따라 3차원으로 표현하게 된다.
》 커널(Kernel)의 종류
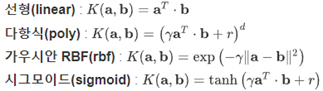
* SVM 요약
》 SVM은 분류에 사용되는 지도학습 머신러닝 모델
》 SVM은 서포트벡터(support vectors)를 사용해서 결정 경계(Decision Boundary)를 정의하고, 분류되지 않은 점을 해당 결정 경계와 비교해서 분류
》 서포트벡터(support vectors)는 결정 경계에 가장 가까운 각 클래스의 점들이다.
》 서포트벡터와 결정 경계 사이의 거리를 마진(margin)이라고 한다.
》 SVM은 허용 가능한 오류 범위 내에서 가능한 최대 마진을 만들려고 한다.
》 파라미터C는 허용되는 오류 양을 조절한다. C값이 클수록 오류를 덜 허용하며 이를 하드 마진(hard margin)이라 부른다. 반대로 C 값이 작을수록 오류를 더 많이 허용해서 소프트 마진(soft margin)을 만든다.
》 SVM에서는 선형으로 분리할 수 없는 점들을 분류하기 위해 커널(kernel)을 사용한다.
》 커널(kernel)은 원래 가지고 있는 데이터를 더 높은 차원의 데이터로 변환한다. 2차원의 점으로 나타낼 수 있는 데이터를 다항식(polynomial) 커널은 3차원으로, RBF 커널은 점을 무한한 차원으로 변환한다.
》 RBF 커널에는 파라미터감마(gamma)가 있다. 감마가 너무 크면 학습 데이터에 너무 의존해서 오버피팅이 발생할 수 있다.
* 기계학습 vs 딥러닝이 차이? : 모델이 다르다
》 딥러닝 : Neural Network(NN)
》 기계학습 : 모델의 종류, Feature를 직접 인간이 선택
* Perceptron(퍼셉트론) : 인간의 생물학적인 뉴런과 인공신경망을 수학적으로 표현한 모델이다.

- X1,X2: 입력, W1,W2: 가중치(퍼셉트론에서의 파라미터), Y: 출력
》 XOR 게이트는 AND와 OR, NOT 게이트의 조합으로 만들 수 있다. (Perceptron으로 여러개로 구현 가능)
》 Multi Layer Perceptron (MLP) : Hidden Later가 3층 이상이 되면 Deep Neural Network (DNN)이라고 한다. 단층 Perceptron일 때는 풀 수 없었던 XOR Gate를 2층으로만 쌓아도 풀 수 있다는 것을 알게 되었다.
- FC(Fully Connected) = MPL = NN (같은 말)
- Perceptron을 여러 개 쌓은 MLP 모델이 바로 DNN이고, 이를 학습시키면 바로 Deep-Learning
》 MPL 학습과정 : 계산 값과 정답의 차이를 작게 만들어 나가는 과정이 학습과정이며, 새로운 w는 기준 w에서 수정 값을 빼는 것 수정 값은 learning rate, gradient, cost function으로 구성되어 있다.
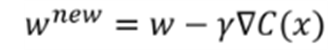
》 오차함수(MSE) : 최소제곱법(Minimum Squared Error)차이를 제곱해서 평균을 내는 방법

》 가장 기본적인 오차함수: ACE

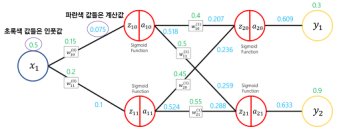
》 역전파(Backpropagation)
- 순전파, Y1은 줄이는 방향, Y2는 증가하는 방향
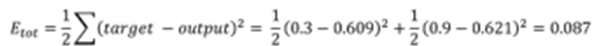
》 Vanishing Gradient : 이제 학습과정이 어떻게 되는지 제대로 알았으니 더 어렵고 더 복잡한 문제를 풀 수 있다. 더 깊은 망을 학습시키는 과정에서 Output값과 멀어질수록 학습이 잘 안되는 현상들이 발생한다. 이 현상을 Vanishing Gradient라고 부름
(이 현상 때문에 다시 인공신경망연구에 침체기가 도래)
* Ovefitting(과적합) : 제한된 샘플에 너무 특화가 되어, 새로운 샘플에 대한 예측 결과가 오히려 나빠지거나 학습의 효과가 나타나지 않는 경우(모델이 데이터보다 더 클 때, 데이터의 양이 너무 적을 때 발생)

》 Overfitting(과적합) 문제를 해결하는 방법(3가지)
1. 더 많은 데이터를 사용할 것
2. Cross Validation
3. Regularization
》 Regularization : 기본적인 컨셉은 큰 coefficient 즉, weight에 페널티를 주는 것
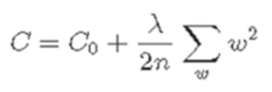
- L2 regularization
- C0:원래 cost function
- N: numof data
- W: weight
- Lamda: 변수(0 ~ 1 값)
이 글의 내용 및 그림, 사진 등의 콘텐츠는 작성자에게 저작권이 있습니다.
이를 무단으로 복제, 수정, 배포하는 행위는 불법이며, 관련 법률에 의해 엄격하게 제재될 수 있습니다.
작성자의 동의 없이 이 콘텐츠를 사용하는 경우, 민사 및 형사상의 책임을 물을 수 있습니다.
Copyright. 우리의인공지능항해 All rights reserved.
'인공지능(LLM 구축) > 인공지능 기초지식' 카테고리의 다른 글
| 인공지능(AI)과 교육: 현재 상황과 미래 전망 (0) | 2024.02.18 |
|---|---|
| 생성형 인공지능 (Generative AI)에 대한 이해 (0) | 2024.02.12 |
| 핵심으로 알아보는 인공지능 기본 이론(요약 정리) 3 (2) | 2024.01.25 |
| 핵심으로 알아보는 인공지능 기본 이론(요약 정리) 1 (1) | 2024.01.24 |



