* 머신러닝 : 경험적 데이터를 기반으로 학습하고 예측하고 스스로 성능을 향상시키(파라미터가 업데이트 되는 것)는 시스템과 이를 위한 알고리즘을 구현하는 연구분야
- 인공지능 : 인간의 학습능력과 추론능력,지각능력,자연언어의 이해능력 등을 프로그램으로 실현한 기술
- 딥러닝 : 머신러닝의한 분야로 Neural Network를 기반으로 하는 학습모델을 구축하는 연구
- 머신러닝 변천사 : 전문가 시스템(논리/규칙 기반)→인공신경망(연결기반)→기계학습(통계기반)→딥러닝
- 머신러닝 응용 분야 : 문서분류, 감성분석, 번역, 얼굴인식, 주식예측, 로봇제어
- 머신러닝을 하려면 필요한 사항 : 데이터 + 모델
- 데이터(제일중요), 모델(지도, 비지도, 강화학습)
* 모델을 학습한다? : (의미)모델에 존재하는 파라미터를 학습하는 것
- 머신러닝이란 모델이 가변하는 파라미터가 있고, 데이터를 모델에 입력하여 파라미터를 결정 짓는 것
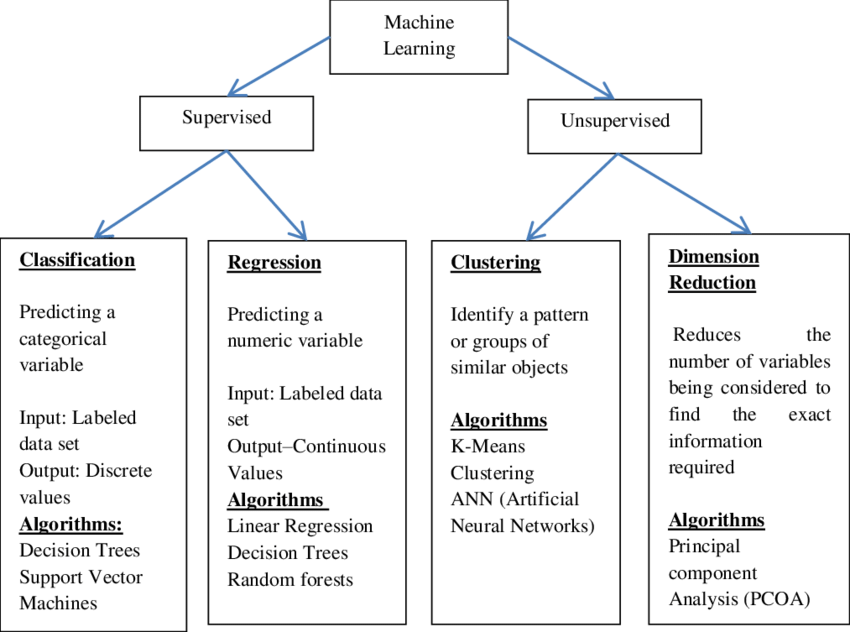
* 머신러닝 분류(학습 방법에 따른 분류)
- 지도학습(Supervised Learning) : 데이터에서 하나의 함수를 유추해 내기 위한 방법, 문제의 종류에 따라 회귀(=예측:특정한 값 찾기)나 분류로 나누어지며, 입력데이터에 결과 값이 포함되어 있음
- 비지도학습(Unsupervised Learning) : 데이터가 어떻게 구성되어 있는지 알아내는 방법, 대표적으로 군집화 기술이 있으며 사진분류, 고객분류 등에 쓰인다
- 강화학습(Reinforcement Learning) : 어떤 환경에서 보상을 최대로 하는 행동을 선택하는 방법, 입력에 대한 출력과 점수를 통해 학습하게 되는데, 주로 게임에서 사용되는 학습 방법
* 인간처럼 생각하는 기계란? : 반응이 인간처럼 나오는 것스스로 학습하는 기계(이미테이션 게임 = 튜링테스트)
- 튜링테스트 : 얼마나 인간과 비슷하게 대화할 수 있는지를 통해 기계의 지능을 판단할 수 있는 테스트
- 기계가 질문했는지, 인간이 질문했는지 인간이 질문하는 것
* 딥러닝과 머신러닝의 차이? : 모델이 다른 것
- 기계학습보다 딥러닝이 좋다 => 기계학습은 사람이 feature를 정해줘야 한다. 딥러닝은 이 feature를 Neural Network라는 모델이 정해 준다.
- 딥러닝은 모델을 정하고 데이터만 입력해 주면 파라미터를 알아서 찾아준다.(gradient descent 방법)
- 데이터가 많을 때 : 딥러닝, 적을 때 머신러닝
* 머신러닝에서 필요한 수학 지식
- 선형대수(벡터와 행렬), 확률통계(조건부 확률, 베이즈정리, 정보이론), 미분(경사하강법, 최적화)
* 데이터란? : 좌표축 위의 점
- 데이터는 사진, 동영상, 신호 등 여러 형태가 있겠지만 좌표축 위에 물리량이 부여된 점
- 좌표 축 = Feature(특징)
* 벡터의 길이와 내적
- 두 점 사이의 거리(= 두 데이터의 차이) : 두 벡터 사이의 거리는 두 벡터의 내적 값을 비교하여 어떤 데이터가 가까운지 찾는 것
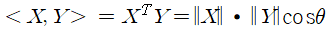
* 최적화 이론 : 최적화(optimization) 문제란 어떤 목적함수(objective function)의 함수 값을 최적화(최대화 또는 최소화)시키는 파라미터(변수) 조합을 찾는 문제
- - (순서) ①목적함수 설정 ②최소화 or 최대화
- - 오차(예측값과 실제 값의 차)를 최소화 하는 것
- - RMS(root mean square) : 평균 제곱

* 모델의 파라미터를 구하는 것 : Cost를 최소화 시키는 Parameter를 찾는 것(미분을 사용하여 파라미터를 업데이트하는 방법을 알려준다) = 스스로 학습하는 것
- Gradient descent(경사하강법) → 최적화 과정
- 편미분, 기울기(Gradient) : 미분은 함수의 기울기를 구할 때 쓰이며, 특징 값을 사용할 때는 기울기가 0인 값이 좋다
* PDF(Probability Density Function) : 확률밀도함수
- 우리가 어떤 현상의 확률을 정확히 안다는 것은 PDF를 알고 있다는 의미
- 확률변수 : 시건들의 집합인 표본공간에서 일정한 확률을 가지고 발생하는 사건에 수치를 일대일 대응시킨 함수(X : 모든 가능한 사건의 집합, x : 특수한 사건이 발생할 확률)
- 확률변수 특징:①0~1사이의 값 ②모든 사건들의 확률 합
* 연속사건의 확률 : 특정 숫자가 나올 확률을 말하는 것은 의미가 없어 다른 방법을 생각해야 하는데, 숫자가 특정 구간에 속할 확률
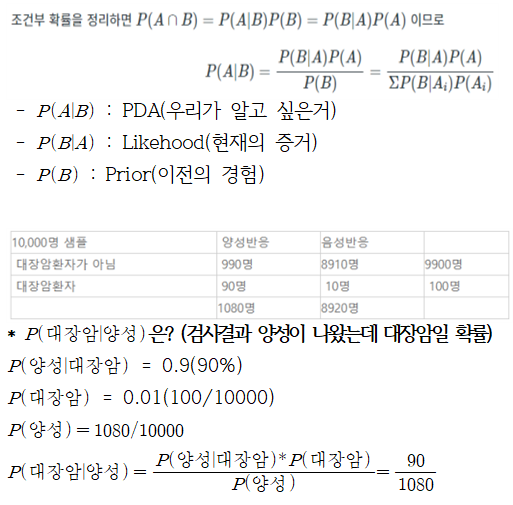
* 조건부 확률 : 사건B가 일어났다는 전제 하에 사건 A가 일어날 확률

* 베이지 이론(Bayes Theorem) : 이전의 경험과 현재의 증거를 토대로 어떤 사건의 확률을 추론하는 알고리즘
* 통계의 본질 : “실제 세계의 문제를 확률분포로써 수학적으로 모델링하고, 가정한 분포의 error를 최소화 하는 방향으로 Parameter를 추정”하는 학문
- 실제 우리가 알고 싶은 어떤 사건의 PDF를 알기 위해서 ①어떤 모델을 만들고 ②데이터를 입력하여 ③PDF를 만든다 ④ 실제 PDF와 일치할 수 있도록 파라미터를 수정해 간다.
* MLE(Maximum Likelihood Estimation) : 𝜃를 estimate하는 방법 중 하나로, Likelihood를 최대로 만드는 값으로 선택하는 것
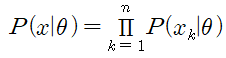
* 엔트로피란 : 불확실성을 나타내는데, 정보량의 평균
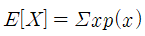
* 엔트로피(정보량의 평균) :

* 크로스엔트로피(틀릴 수 있는 정보를 가지고 구한 엔트로피)
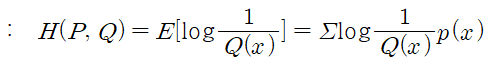
- Q(x) : 모델로 만든 PDF(예측), P(x) : 실제 PDF
- PDF 두 개를 비교할 경우는 크로스엔트로피 사용, 그냥 값 두 개를 비교할 경우 RMS사용(최적화이론)
* KL-divergence : 두 개의 PDF가 비슷한지 계산하는 함수
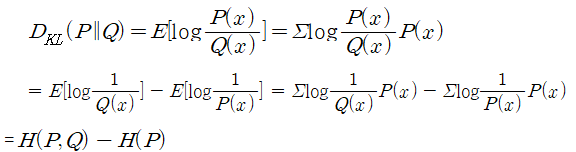
- P(x)와 Q(x)가 동일하면 cross entropy = entropy가 되면서 최소값이 되고.. 서로 많이 다르면 그 값이 커지는 구조
* 엔프로피란 : 불확실성을 나타내는데, 정보량의 평균
- 선형대수 : 벡터와 행렬을 다루는 학문
- 머신러닝 : 데이터를 좌표축 위에 점으로 표시를 하고, 이 데이터를 잘 분류하게 하는 행동이다.
- 최적화 : Cost function 최소화 or Likelihood 값을 최대화 시키는 값을 구하는 것
머신러닝을 사용하기 위해서는 데이터 탐색을 제대로 하고, 쓸모 있는 피쳐들이 구성된 양질의 데이터를 입력해야지만 같은 모델을 사용하더라고 의미있는 결과를 얻을 수 있다.
* Regression 종류
1. Linear Regression(선형 회귀) : 예측(특정한 값 찾기)
- Cost함수 : MSE(Minimum Squared Error)
2. Logistic Regression(로지스틱 회귀) : 둘중에 하나 고르는 것(=Perceptron)
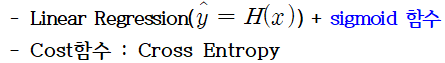
3. Softmax Regression(소프트맥스 회귀) : 여러개중에 하나 고르는 것(다중 클래스 분류)
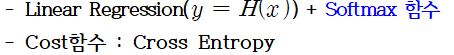
* Classification 모델의 Cost함수 : 크로스엔트로피
- 오차함수(MSE) : 최소제곱법(Minimum Squared Error)차이를 제곱해서 평균을 내는 방법
이 글의 내용 및 그림, 사진 등의 콘텐츠는 작성자에게 저작권이 있습니다.
이를 무단으로 복제, 수정, 배포하는 행위는 불법이며, 관련 법률에 의해 엄격하게 제재될 수 있습니다.
작성자의 동의 없이 이 콘텐츠를 사용하는 경우, 민사 및 형사상의 책임을 물을 수 있습니다.
Copyright. 우리의인공지능항해 All rights reserved.
'인공지능(LLM 구축) > 인공지능 기초지식' 카테고리의 다른 글
| 인공지능(AI)과 교육: 현재 상황과 미래 전망 (0) | 2024.02.18 |
|---|---|
| 생성형 인공지능 (Generative AI)에 대한 이해 (0) | 2024.02.12 |
| 핵심으로 알아보는 인공지능 기본 이론(요약 정리) 3 (2) | 2024.01.25 |
| 핵심으로 알아보는 인공지능 기본 이론(요약 정리) 2 (2) | 2024.01.24 |

댓글