* Cost가 작아지는 방향뿐만 아니라 w가 최소가 되는 방향으로 학습(Weight 값이 작아지면 데이터의 실뢰성, 성능이 더 좋다고 평가할 수 있다)
》 W가 작아지도록 학습하는 이유 :
- local noise가 학습에 큰 영향을 끼치지 않는다는 것을 의미
- Outlier의 영향을 더 적게 받도록 하겠다는 것
- 일반화에 적합한 특성을 가지도록
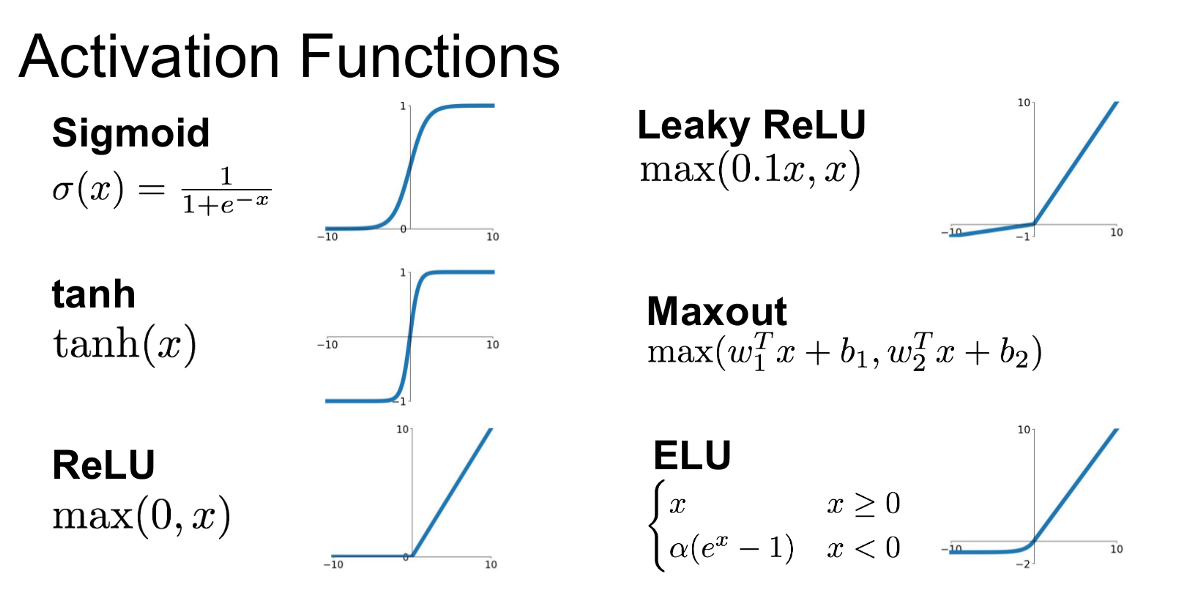
》 활성화 함수(activation function)
- 활성화 함수를 사용하면 입력값에 대한 출력값이 linear하게 나오지 않으므로 선형분류기를 비선형 시스템으로 만들 수 있다.
- 따라서 MLP(Multiple layer perceptron)는 단지 linear layer를 여러개 쌓는 개념이 아닌 활성화 함수를 이용한 non-linear 시스템을 여러 layer로 쌓는 개념이다.
- Softmax함수 : 여러개의 PDF(확률)를 만들 때 사용
* Batch Normalization(BN) : 배치정규화의 필요성: 트레이닝셋과 테스트셋의 확률 분포가 다름
- 깊은 신경망일수록 같은 Input 값을 갖더라도, 가중치가 조금만 달라지면 완전히 다른 값을 가진다. 이를 해결하기 위해, 각 layer에 배치 정규화 과정을 추가해준다면, 가중치의 차이를 완화하여 보다 안정적인 학습이 이루어질 수 있다.
* Transfer Learning : 기존의 만들어진 모델을 사용하여 새로운 모델을 만드는 것 학습이 빨라지며, 예측도 높아짐
- 기계학습 : Feature를 인간이 직접 선정하고,
- Neural Network : 컴퓨터가 Feature를 뽑아주기 때문에
》 왜 사용할까?
- 이미 학습된 모델을 사용해서 문제를 해결 가능
- 실질적으로 network을 처음부터 학습시키는 일은 많지 않다.
- 만들고자하는 모델이 복잡한 모델일수록 학습시키기 어렵다.
- layers의 갯수, activation, hyper parameters등 고려해야 할 사항들이 많다.
- 모델 학습이 오래 걸릴 수도 있다.
- 학습 데이터의 수가 적을 때 효과적이다.
- 또한, 전이학습없이 학습하는 것보다 학습 속도도 빠르며 훨씬 높은 정확도를 제공한다.
- 즉, 이미 잘 훈련된 모델이 있고, 해당 모델과 유사한 문제를 해결 시 transfer learning을 사용
* Fine-tuning : 기존에 학습되어져 있는 모델을 기반으로, 아키텍쳐를 새로운 목적에 맞게 변형하고, 이미 학습된 모델의 파라미터를 업데이트 하는 방법
- 새로 훈련할 데이터가 적지만, original 데이터와 유사할 경우 : 데이터의 양이 적어, 전체 네트워크를 fine-tuning 하는 것은 over-fitting의 위험이 있기에 하지 않는다. 새로 학습할 데이터는 original 데이터와 유사하기 때문에 이 경우 최종 linear classifier layer만 학습
- 새로 훈련할 데이터가 적으며, original 데이터와 다른 경우 : 이 경우 데이터의 양이 적고, 데이터가 서로 다르기 때문에, 네트워크의 마지막 부분만 학습하는 것은 좋지 않으며, 네트워크 초기 부분 어딘가 activation 이후에 특정 layer를 학습시키는게 좋다.
- 새로 훈련할 데이터가 많으며, original 데이터와 유사할 경우 : 새로 학습할 데이터의 양이 많다는 것은, over-fitting의 위험이 낮다는 뜻이므로 전체 layer를 fine-tuning을 하거나, 마지막 몇 개의 layer만 fine-tuning하거나, 마지막 몇 개의 layer를 날려버리는 방법이 있다.
- 새로 훈련할 데이터가 많지만, original 데이터와 다른 경우 : 데이터가 많기 때문에, 아예 새로운 모델을 만들 수도 있지만, 실질적으로 transfer learning의 효율이 더 좋다. 전체 네트워크를 fine-tuning 해도 된다.
* Convolutional Neural Network : 딥러닝이 유명해진 계기(일반 대중들에게 널리 알려진 계기)
- 1988년 Yann LeCun이 최초의 CNN구조를 만들어냄
- 초반에는 간단 시각정보(edge)를 먼저 수집하고 이를 기반으로 뒤로 갈수록 좀 더 추상적인 정보를 담을 수 있도록
- 데이터를 자르지 않고, 기존지식을 이용해 전체적으로 공간적인 네트워크 구조(특징 추출)를 특수한 형태로 변형시켜주는 것
- 데이터의 특징에 따라서 모델도 그에 맞게 만들어주면 더 잘된다.
》 고양이의 시각피질검사 : 인간의 신경망을 본떠 DNN을 만든 것 처럼, CNN도 시각피질(visual cortex)의 neuron이 어떻게 작동하는지 파악
고양이에게 단순한 모양의 여러패턴을보여주고 시각 피질의 반응을 살펴봄
패턴에 따라 뉴런이 반응하는 정도가 다르다
고양이의 시각 피질은 흑백이미지에서 밝기가 변하는 사선이나 배경색과 대조되는 사선 즉 edge를 detect한다.
》 영상 특징점(Key point) :
- 물체의 형태나 크기, 위치가 변해도 쉽게 식별이 가능할 것
- 카메라의 시점, 조명이 변해도 영상에서 해당 지점을 쉽게 찾아낼 수 있을 것
- 영상에서 이러한 조건을 만족하는 가장 좋은 특징점이 바로 엣지(edge)나 코너 (corner)
》 Filter : 그 특징이 데이타에있는지 없는지를 검출해주는 함수이다.
- 예를 들어 아래와 같이 곡선을 검출해주는 필터가 있다고 하자, 받은 이미지 역시 행렬로 변환이 되는데 쥐 그림에서 좌측 상단의 이미지 부분을 잘라내서 필터를 적용하는 결과
- 필터는 입력받은 데이터에서 그 특성을 가지고 있으면 결과 값이 큰 값이 나오고, 특성을 가지고 있지 않으면 결과 값이 0에 가까운 값이 나오게 돼서 데이터가 그 특성을 가지고 있는지 없는지 여부를 알 수 있게 해준다.

》 정형 vs 비정형 데이터 차이 : 정형 데이터는 데이터베이스에서 데이터의 체계를 기반으로 예측 가능한 방식으로 검색할 수 있게끔 설계됩니다. 반면 비정형 데이터는 그렇지 않습니다. 비정형 데이터에는 예측 또는 사전 정의가 가능한 포맷 또는 체계가 없습니다.
》 Softmax 함수의 결과 값은 : PDF
- 내 CNN 모델이 만든 PDF => 예측 PDF
- 실제 PDF = 0, 1, 0, 1, 1 ...
일 때, 이 두 개의 PDF를 비교하기 위한 Cost함수는?
(정답) : 크로스엔트로피
=> Cost함수 종류 : (MSE, 크로스엔트로피) 이며
=> Cost함수 결과값은 낮을수록 좋다.
(정답 PDF와 예측 PDF의 차이가 작다)
》 CNN의 흐름과 장점
기계학습 → 딥러닝(Neural Network)으로 변화했고,
딥러닝은 Feature도 모델이 찾아준다.
데이터가 비정형 → 정형의 형태로 변경되고,
이미지의 경우 공간적인 정보를 갖고 있기 때문에
Neural Network 모델을 구성할 때 여러 개의 Filter를 사용하여 파라미터의 수도 줄어들고, 학습도 더 잘되며, 공간적인 정보도 잘 반영이 되었다.
》 CNN 구조
- CNN은 기존 Fully Connected Neural Network와 비교하여 어떠한 차별성이 있나?
- 각 레이어의 입출력 데이터의 형상 유지
- 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식
- 복수의 필터로 이미지의 특징 추출 및 학습
- 추출한 이미지의 특징을 모으고 강화하는 Pooling 레이어
- 필터를 공유 파라미터로 사용하기 때문에, 일반 인공 신경망과 비교하여 학습 파라미터가 매우 적음
- CNN은 아래와 같이 이미지의 특징을 추출(Feature Extraction)하는 부분과 클래스를 분류(Classification)하는 부분으로 나눌 수 있다
- 특징 추출 영역은 Convolution Layer와 Pooling Layer를 여러 겹 쌓는 형태로 구성
》 Feature Map : Input 영상에서 Convolution을 하고 나서 나오는 결과 영상의 모음(특징들을 매핑한 결과 영상) = 컨볼루션 레이어를 거친 결과

》 Feature Map 관련 문제
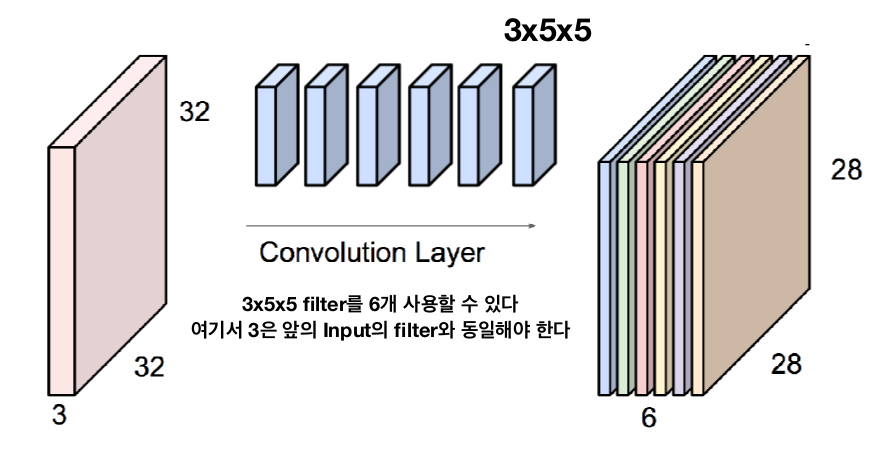
- 학습해야할 파라미터의 개수 : 3*5*5*6 = 450
》 패딩(Padding) : Convolution 레이어에서 Filter와 Stride에 작용으로 Feature Map 크기는 입력 데이터 보다 작다.
- Convolution 레이어의 출력 데이터가 줄어드는 것을 방지하는 방법이 패딩.
- 패딩은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣는 것을 의미(보통 패딩 값으로 0)
》 스트라이드(Stride) : 필터는 입력 데이터를 지정한 간격으로 순회하면서 합성곱을 계산.
- Stride: 지정된 간격으로 필터를 순회하는 간격
- Stride는 쉽게 말해 필터를 얼마만큼 움직여 주는가
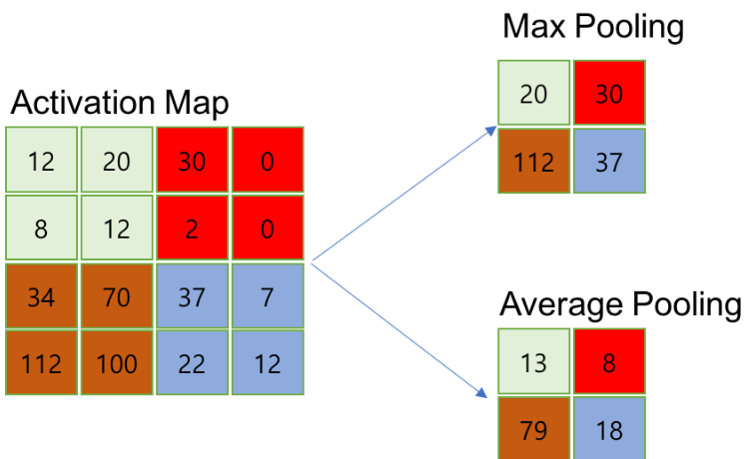
》 Pooling(subsampling) : Feature Map의 모든 특징을 가지고 판단 → 비효율적
- Input 이미지가 너무 해상도가 높은 것 보다는 해상도를 낮춰주는 것이 성능에 더 좋다는 특징
Ex) 고해상도 사진을 보고 물체를 판별할 수 있지만, 작은 사진을 가지고도 그 사진의 내용이 어떤 사진인지 판단할 수 있는 원리
추출된 Activation map을 인위로 줄이는 작업 → sub sampling /pooling
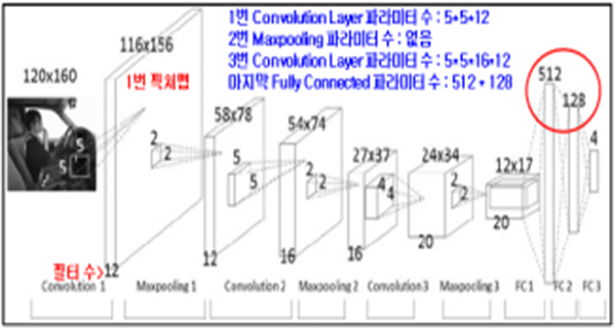
》 Dropout : Fully connected 네트워크와 Softmax함수 중간에 Dropout layer (드롭아웃) 라는 계층이 있는 것을 볼 수 있다.
- 드롭 아웃은 오버피팅(over-fit)을 막기 위한 방법으로 뉴럴 네트워크가 학습중일 때,
- 랜덤하게 뉴런을 꺼서 학습을 방해함으로써, 학습이 학습용 데이터에 치우치는 현상을 막아준다.

* Recurrent Neural Network
》 Sequential Data : 순서가 의미가 있으며, 순서가 달라질 경우 의미가 손상되는 데이터를 순차 데이터라고 한다.
시간적의미가 있는 경우 Temporal Sequence라고 하며, 일정한 시간차이면 Time Series라고 한다,
순차데이터는 보통 가변길이이다.
기존의 뉴럴네트워크 알고리즘은 이미지처럼 고정된 크기의 입력을 다루는 데는 탁월하지만,
가변적인 크기의 데이터를 모델링하기에는 적합하지 않다.
- 데이터 유형 : Time-series, Ordered
(센서 데이터, 주가 변동, 지진파, 그리고 DNA 염기서열 등)
- 과거에 들어온 입력이 현재 들어온 입력에 영향을 줄 수 있게 설계한 모델
》 순차 데이터셋의 구조 :
1. 다중 입력, 단일 출력 : AI 개인 비서 서비스
- 올바른 대답을 하려면, 입력을 받을 때 마다 그 내용을 ‘기억’할 수 있어야 한다.
2. 다중 입력, 다중 출력 : 번역기
3. 단일 입력, 다중 출력 : 사진을 묘사하는 장면 이해
》 기존 신경만의 한계 : 지금까지 본 Neural Network Architecture는 현재 입력을 통해서만 학습
현재 출력을 생성할 때 이전 입력을 고려하지 않음
우리 시스템에는 메모리 요소가 없었음
RNN은 현재 출력을 생성 할 때 메모리 (즉, 네트워크에 대한 과거 입력)를 사용하여 매우 기본적이고 중요한 문제를 해결
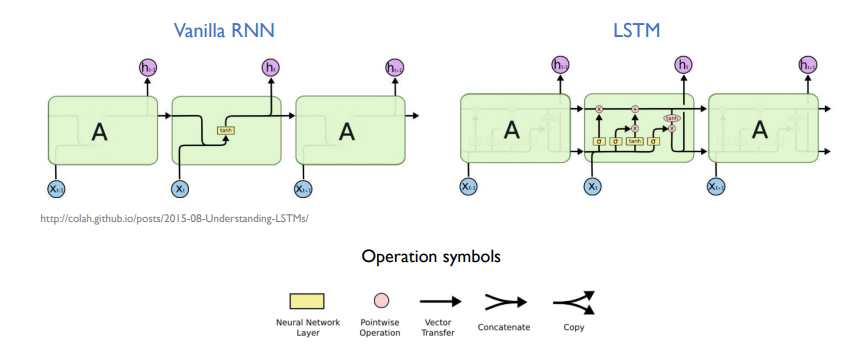
》 RNN 특징 :
- 순서가 중요 하다
- Hidden state가 존재 한다
- Weight를 공유 한다
- 응용 구조를 만들기 쉽다
- 모델의 크기가 hidden state 크기에 의존한다.
* Vanilla RNN : RNN에 대한 기본적인 아이디어는 순차적인 정보를 처리한다는 데 있다(기본적인RNN)
* LSTM(Long Short-Term Memory) : 장단기 기억 능력이 더 우수한 모델이다.
- RNN을 개선하기 위한 모델
이 글의 내용 및 그림, 사진 등의 콘텐츠는 작성자에게 저작권이 있습니다.
이를 무단으로 복제, 수정, 배포하는 행위는 불법이며, 관련 법률에 의해 엄격하게 제재될 수 있습니다.
작성자의 동의 없이 이 콘텐츠를 사용하는 경우, 민사 및 형사상의 책임을 물을 수 있습니다.
Copyright. 우리의인공지능항해 All rights reserved.
'인공지능(LLM 구축) > 인공지능 기초지식' 카테고리의 다른 글
| 인공지능(AI)과 교육: 현재 상황과 미래 전망 (0) | 2024.02.18 |
|---|---|
| 생성형 인공지능 (Generative AI)에 대한 이해 (0) | 2024.02.12 |
| 핵심으로 알아보는 인공지능 기본 이론(요약 정리) 2 (2) | 2024.01.24 |
| 핵심으로 알아보는 인공지능 기본 이론(요약 정리) 1 (1) | 2024.01.24 |



