안녕하세요. 우리의 인공지능 항해사 유로젠입니다.
이번에는 Generative Adversarial Network (GAN) 모델의 개념에 대해 이야기하려고 합니다.
GAN(Generative Adversarial Networks, 생성적 적대 신경망)이란 비지도학습에 사용되는 머신러닝 프레임워크의 한 종류이다.
GAN은 Generative Adversarial Networks 의 줄임말로, Generative Model의 한 종류입니다. 우리말로는 적대적 생성 신경망이라고 합니다. GAN은 실제에 가까운 이미지나 사람이 쓴 것과 같은 글 등 여러 가짜 데이터들을 생성하는 모델입니다.
1. GAN 배경 및 개요
○ GAN (Generative Adversarial Network: 생산적 적대 신경망)은 2014년, Ian Goodfellow의 "Generative Adversarial Network"라는 논문에서 처음 제시되었다.
GAN은 Neural Network에 뿌리를 두고 있으나 비지도 학습으로 정의되며, 두 개의 신경망이 서로 경쟁하며 학습하게 된다. 처음 아이디어가 제안된 이후, 급격한 연구적 성장을 거듭하며 현재는 놀라울 정도로 진보된 기술로 성장하고 있으며, 아래 이미지는 GAN이 제시된 2014년부터 2020년까지 GAN을 주제로 한 논문 수를 나타내는 도표로, 상당히 빠른 속도로 많은 사람에게 연구가 되어오고 있음을 확인할 수 있다.
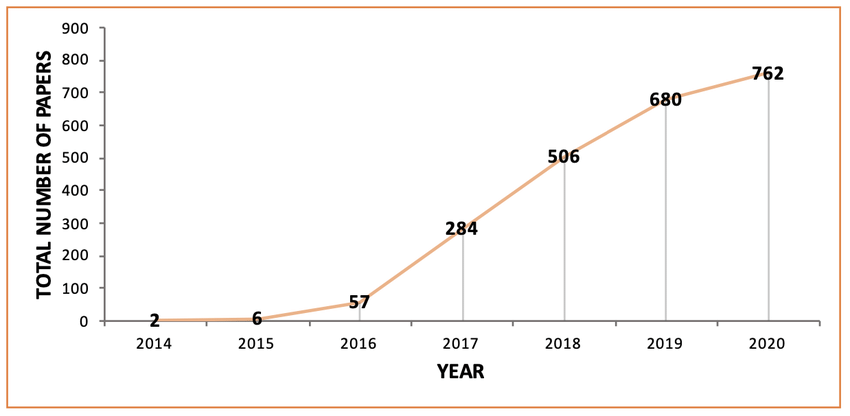
○ 페이스북 인공지능 연구팀의 리더이자 딥러닝의 아버지라 불리는 얀 르쿤(Yann LeCun) 교수는 GAN(Generative Adversarial Network)을 가리켜 최근 10년간 머신러닝 분야에서 가장 혁신적인 아이디어라고 말했다. 요즘 가장 주목받는 기술인 딥러닝 중에서도 GAN은 가장 많은 관심을 받으며 새로운 연구가 활발히 이루어지고 혁신이 빠르게 일어나고 있는 기술이기도 하다. 3D 물체 생성(3D object generation), 의학, 이미지 처리(Image processing), 안면인식(Face detection), 문자 관련, 교통 통제(Traffic control) 등 다양한 분야에서 GAN 기법을 사용하여 새로운 돌파구를 마련해오는 연구가 지속되어 오고 있다. GAN을 활용해 이전에 없었던 서비스나 제품이 출시되고 우리 삶에 깊숙이 자리 잡을 날도 얼마 남지 않은 듯이 보인다.
2. GAN 개념(Concept)
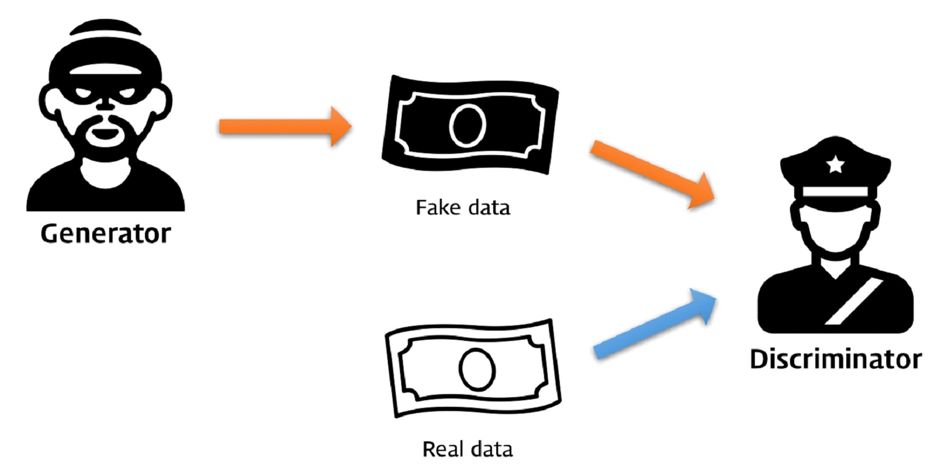
○ GAN의 구조를 흔히 '경찰'과 '위조지폐범'에 빗대어 설명한다. 위조지폐범(Generator)이 위조지폐를 생성하면, 경찰(Discriminator)은 위조지폐와 진짜 지폐를 보고 어느 것이 진짜/가짜인지를 가려내는 역할을 한다. 위조지폐범은 최대한 진짜 같은 지폐를 만들어 경찰을 속이고, 경찰은 위조지폐범이 만들어낸 지폐와 진짜 지폐를 대조하면서 둘을 구분할 수 있는 차이점을 계속해서 찾아내게 된다. 위조지폐범에 해당하는 생성자(Generator)와 경찰에 해당하는 구분자(Discriminator)가 서로 경쟁적인 학습이 계속되다 보면, 어느 순간 경찰이 진짜 지폐와 구분할 수 없을 정도로 비슷한 지폐를 만들 수 있게 될 것이다. 이것이 GAN의 핵심적인 아이디어인 적대적 학습(Adversarial Training)이다.
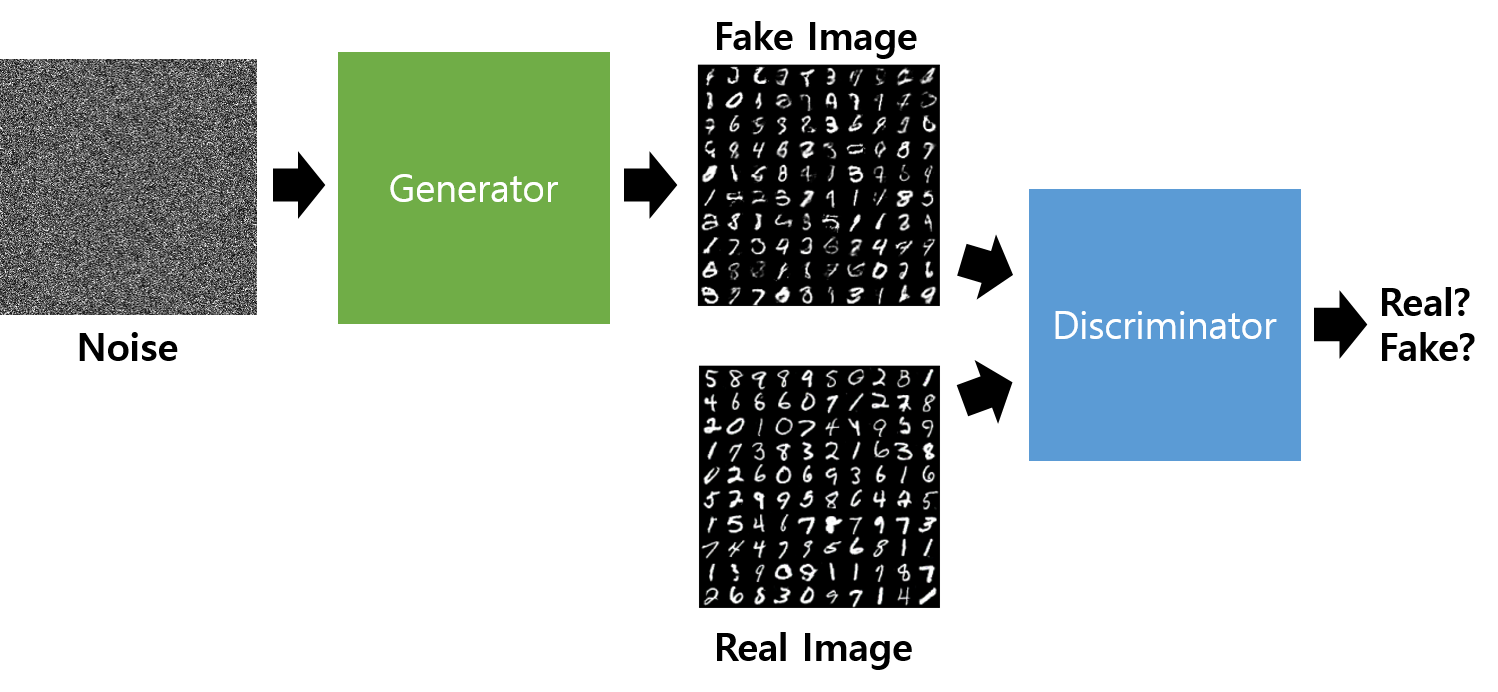
○ Generator는 real data의 distribution을 학습해 fake 데이터를 만드는 일을 한다.
→ 최종적으로 이를 Discriminator가 최대한 헷갈리게 하는 것을 목표로 한다.
○ Discriminator는 smaple이 realdata(training)인지 아닌지를 구분한다.
→ 최종적으로 Fake 이미지를 최대한 잘 판별하는 것 을 목표로 한다.
* Brief introduction to GAN
| ○ GAN은‘Generative Adversarial Network’의 약자다. 이 세 글자의 뜻을 풀어보는 것만으로도 GAN에 대한 전반적으로 이해할 수 있다. 첫 단어인 ‘Generative’는 GAN이 생성(Generation) 모델이라는 것을 뜻한다. 생성 모델이란 ‘그럴듯한 가짜’를 만들어내는 모델이다. 언뜻 보면 진짜 같은 가짜 사람 얼굴 사진을 만들어내거나 실제로 있을 법한 고양이 사진을 만들어내는 것이 생성 모델의 예다. ○ 널리 알려져 있다시피 인공신경망 알고리즘은 인간 뇌 속 뉴런의 행동 방식에 영감을 받아 만들어졌다. 이전 층(Layer)의 뉴런의 출력값에 가중치(Weights)나 매개 변수(Parameters)를 곱해 합한 것이 다음 층 뉴런의 입력값이 된다. 이 입력값에 활성 함수(Activation Function)라 불리는 비선형 함수를 적용시키면 선형 함수로 표현할 수 없는 복잡한 관계를 표현할 수 있게 된다. 딥러닝의 강력함은 이런 층들이 매우 깊게 쌓을 수 있다는 점에서 나온다. 층을 많이 쌓을수록 더욱 복잡한 함수를 표현할 수 있는 힘(Representation Power)을 얻게 된다. ○ 딥러닝을 학습시킨다는 것은 최적의 가중치를 찾아간다는 것을 의미한다. 가중치는 처음에 랜덤으로 초기화되지만, 모델의 손실 함수(Loss Function)을 최소화시키는 방향으로 조금씩 업데이트된다. 이때 손실 함수 값이 역전파를 통해 각 층의 가중치에 전달되며 업데이트 방향과 크기를 결정한다. 이런 방식으로 가중치를 최적화하는 방식을 경사하강법(Gradient Descent)이라고 부른다. ○ 딥러닝은 이론적으로 어떤 함수도 근사할 수 있는 함수(Global Function Approximator) 라는 것이 알려져 있다. 이것이 딥러닝이 개와 고양이 사진을 분류하는 문제에서부터 영어를 한국어로 번역하고, 이세돌 9단을 이기는 바둑 알고리즘을 만드는 데까지 널리 쓰이는 이유다. GAN은 실제 데이터 분포를 근사하는 함수를 만들기 위해 이러한 딥러닝 구조를 활용한다. ○ GAN은 생성이라는 문제를 풀기 위해 딥러닝으로 만들어진 모델을 적대적 학습이라는 독특한 방식으로 학습시키는 알고리즘이다. 이처럼 ‘Generative Adversarial Network’라는 이름 속에는 모델의 목적부터 학습 방법까지 GAN의 전반적인 개념이 모두 들어있다. "Adversarial"이란 단어의 사전적 의미를 보면 대립하는, 적대하는란 뜻을 갖는다. 대립하려면 어찌 되었든 상대가 있어야 하니 GAN은 크게 두 부분으로 나누어져 있다는 것을 먼저 직관적으로 알 수 있다. |
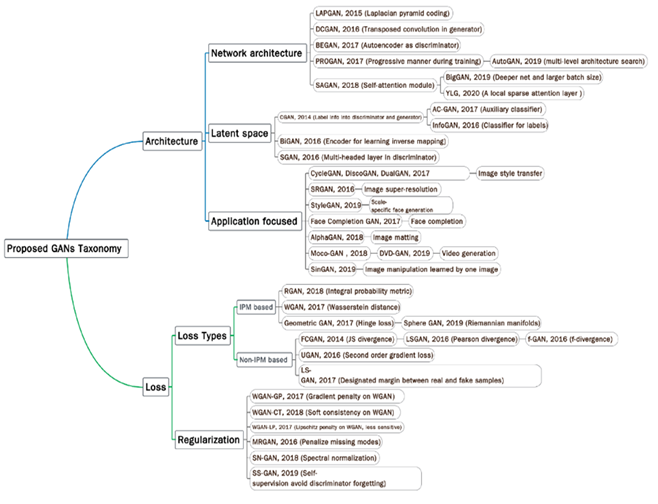
○ 최근 많은 GAN 연구들은 두 가지 objective에 집중하고 있다.
(1) 학습의 개선
(2) Real-world application
○ 학습 과정을 개선시킴으로써, GAN의 성능에 다음과 같은 방향으로 기여할 수 있다.
(1) 생성된 이미지의 diversity의 개선 (mode diversity)
(2) 생성된 이미지의 quality의 개선
(3) 학습의 안정화 (e.g., vanishing gradient issue for generator)
○ 이렇게 GAN의 성능을 개선하기 위한 다양한 GAN-variant들이 제안되어 왔고, 이를 두 가지로 분류할 수 있다.
(1) 모델 구조를 개선하는 방법 - Architecture-variant
(2) Loss의 관점에서 접근하는 방법 - Loss-variant
3. GAN 모델 소개

○ 기본적인 구조 : 가짜 이미지 생성을 위한 생성자(Generator) 신경망과 진짜와 가짜 이미지 판별을 위한 판별자(Discriminator) 신경망으로 구성되며, 두 신경망 모두 FC(Fully Connected Layers)로 구성된 다층 신경망이다.
가. 생성자 네트워크
비지도 학습으로 정의되는 GAN의 생성자는 임의로 생성된 잡음을 입력으로 영상을 생성한다. 보통 1 x 100 ~ 200의 잡음을 입력하며, 기존 MLP와 동일하게 2 ~ 3개의 층으로 구성된 네트워크로 설계한다. MNIST 데이터를 목표할 경우, 28 x 28의 이미지 크기에 맞게 1 x 768의 출력층을 가지게 되며, CNN 구조가 없으므로 2차원 데이터를 모두 1차원으로 변경해 주어야 한다.
나. 판별자 네트워크
생성자 네트워크와 역순으로 설계하며, 1 x 768이 입력되며 신경망 층을 통해 최종적으로 참 (1) 과 거짓 (0)을 판단하게 된다. 손글씨 인식을 위한 분류 네트워크와 같은 구조이며 출력은 1개(1:Real, 0:Fake) 이다.
다. 손실 함수
GAN은 일반적으로 판별자 네트워크 기반 크로스 앤트로피 손실 함수를 통해 학습한다.생성자 네트워크 (G)는 거짓 이미지가 판별자 네트워크에 입력되었을 때 값이 최소(MIN)가 되도록 하며 (거짓 이미지가 거짓인지 모르도록), 판별자 네트워크 (D)는 거짓 이미지와 참 이미지가 판별자 네트워크에 입력되었을 때 값이 최대 (MAX) (거짓을 거짓으로 참을 참으로 판별하도록)가 되도록 학습하게 된다.
이처럼 서로 반대되는 방향으로 학습되는 구조이기 때문에, 경쟁학습 이라고도 하며 Zero-Sum 게임과 유사하다.
○ GAN의 최종 목적은 진짜 데이터 분포와 최대한 근사하는 분포를 학습하고, 결국 분포를 근사하는 것이 GAN의 목표이며, objective는 다음과 같이 나타낼 수 있다.

→ 여기서 V(D,G)의 값은 확률값으로 도출되는데, 이 수식을 각각 D와 G의 관점에서 살펴보면 다음과 같다.
→ 먼저 D의 관점에서 실제 데이터(x)를 입력하면 D(x)가 커지면서 log값이 커지면서 높은 확률값이 나오도록 하고, 가짜 데이터(G(z))를 입력하면 log값이 작아짐에 따라 낮은 확률값이 나오도록 학습된다. 다시 말해 D는 실제 데이터와 G가 만든 가짜 데이터를 잘 구분하도록 조금씩 업데이트되는 것이다.
→ G에서는 Zero-Mean Gaussian 분포에서 노이즈 z를 멀티레이어 퍼셉트론에 통과시켜 샘플들을 생성하며 이 생성된 가짜 데이터 G(z)를 D에 input으로 넣었을 때 실제 데이터처럼 확률이 높게 나오도록 학습된다. 즉 D(G(z))값을 높도록, 그리고 전체 확률 값이 낮아지도록 하는 것이며 이는 다시 말해 G가 ‘D가 잘 구분하지 못하는’ 데이터를 생성하도록 조금씩 업데이트되는 것이다.
→ 실제 학습을 진행할 때는 G와 D 두 네트워크를 동시에 학습시키지 않고 하나의 네트워크를 고정한 상태에서 다른 한 네트워크를 업데이트하는 방식으로 따로따로 업데이트한다.
○ 다른 deep generative models (DGM)과 비교했을 때 GAN의 장점은 다음과 같다.
(1) 다른 DGM 보다 더 나은 output 생성.
(2) 어떤 generator network도 backbone으로 이용할 수 있음.
(3) latent variable의 크기에 대한 제약이 없음.
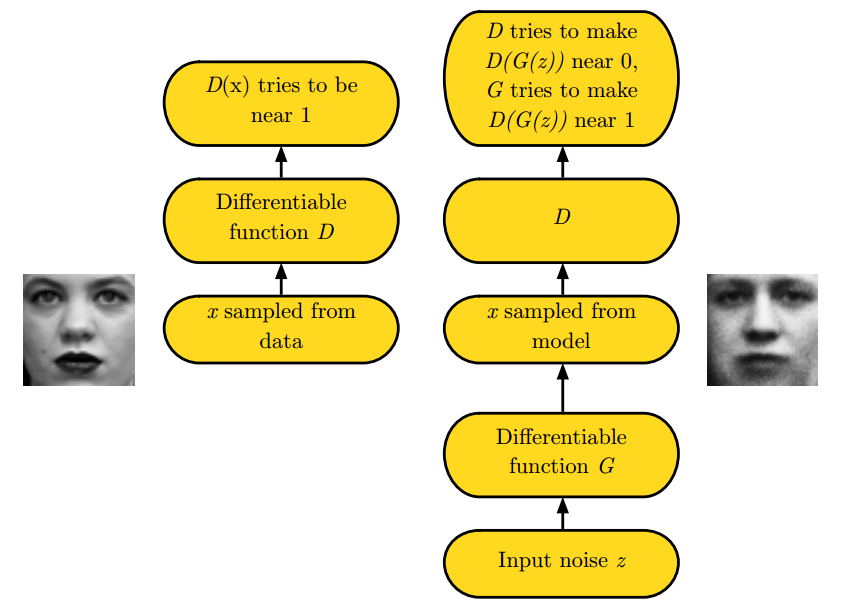
○ 위 그림을 보면 알 수 있듯이 D의 입장에서는 data로부터 뽑은 sample x는 이 되고, 에 임의의 noise distribution으로부터 뽑은 input z 넣고 만들어진 sample에 대해서는 가 되도록 노력한다. 즉, 는 실수할 확률을 낮추기(mini) 위해 노력하고 반대로 는 가 실수할 확률을 높이기(max) 위해 노력하는데, 따라서 둘을 같이 놓고보면 "minimax two-player game or minimax problem" 이라 할 수 있겠다.
○ Generator's distribution pg over data x를 학습하기 위해 generator의 input으로 들어갈 noise variables pz(z)에 대한 prior를 정의하고, data space로의 mapping을 G(z;θg)라 표현할 수 있다. 여기서 G는 미분 가능한 함수로써 θg를 parameter로 갖는 multilayer perceptron이다.
○ 한편, Discriminator 역시 multilayer perceptron으로 D(x;θd)로 나타내며 output은 single scalar 값이 되겠다(확률이므로). D(x)는 x가 pg가 아닌 data distribution으로부터 왔을 확률을 나타낸다. 따라서, 이를 수식으로 정리하면 다음과 같은 value function V(G,D)에 대한 minimax problem을 푸는 것과 같아진다.
4. 생성 모델 (Generative Model)의 목표
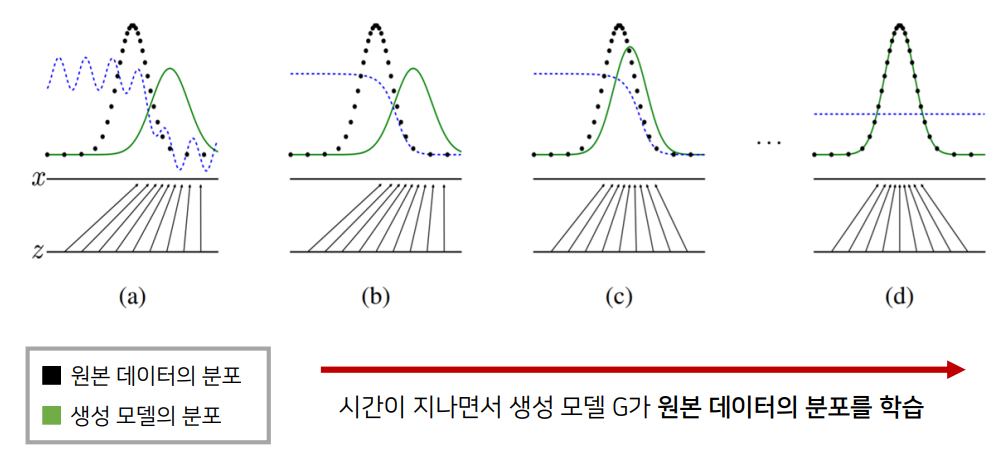
○ 처음 시작할 때는 (a)와 같이 Pg가 Pdata와 전혀 다르게 생긴 것을 볼 수 있고 이 상태에서 discriminator가 두 distribution을 구별하기 위해 학습을 하면 (b)와 같이 좀 더 smooth하고 잘 구별하는 distribution이 만들어진다. 이후 G가 현재 discriminator가 구별하기 어려운 방향으로 학습을 하면 (c)와 같이 좀 더 Pg가 Pdata 와 가까워지게 되고, 이런 식으로 쭉 학습을 반복하다 보면 결국에는 Pg = Pdata 즉 완전히 똑같은 분포를 하게 되어 discriminator가 둘을 전혀 구별하지 못하는 즉, D(x) = 1/2 에 수렴하게 된다.
○ 모델 G의 학습이 잘 되었다면 원본 데이터의 분포를 근사할 수 있으며, 학습이 잘 되었다면 통계적으로 평균적인 특징을 가지는 데이터를 쉽게 생성할 수 있다.

이 글의 내용 및 그림, 사진 등의 콘텐츠는 작성자에게 저작권이 있습니다.
이를 무단으로 복제, 수정, 배포하는 행위는 불법이며, 관련 법률에 의해 엄격하게 제재될 수 있습니다.
작성자의 동의 없이 이 콘텐츠를 사용하는 경우, 민사 및 형사상의 책임을 물을 수 있습니다.
Copyright. 우리의인공지능항해 All rights reserved.
'인공지능(LLM 구축) > AI 및 ML 알고리즘 소개' 카테고리의 다른 글
| Deep Learning 인공지능(AI) 시대 CPU의 발전 방향은? (2) | 2024.01.23 |
|---|---|
| 최신 기술 동향과 함께 알아보는 Advanced GAN (2) | 2024.01.22 |
| GAN의 한계와 극복 전략: 전문가의 시선으로 살펴보는 최신 연구 동향과 해결 방법 (0) | 2024.01.22 |
| GAN 모델의 전문적인 증명 분석 (0) | 2024.01.22 |
| GAN 동작 원리(How to work) (2) | 2024.01.21 |



